VLA(视觉语言动作模型)入门学习路线(第一阶段)
具身智能|VLA(视觉语言动作模型)入门笔记
前言:关于Vision-Language-Action Model
入门必读:《A Survey on Vision-Language-Action Models for Embodied AI》
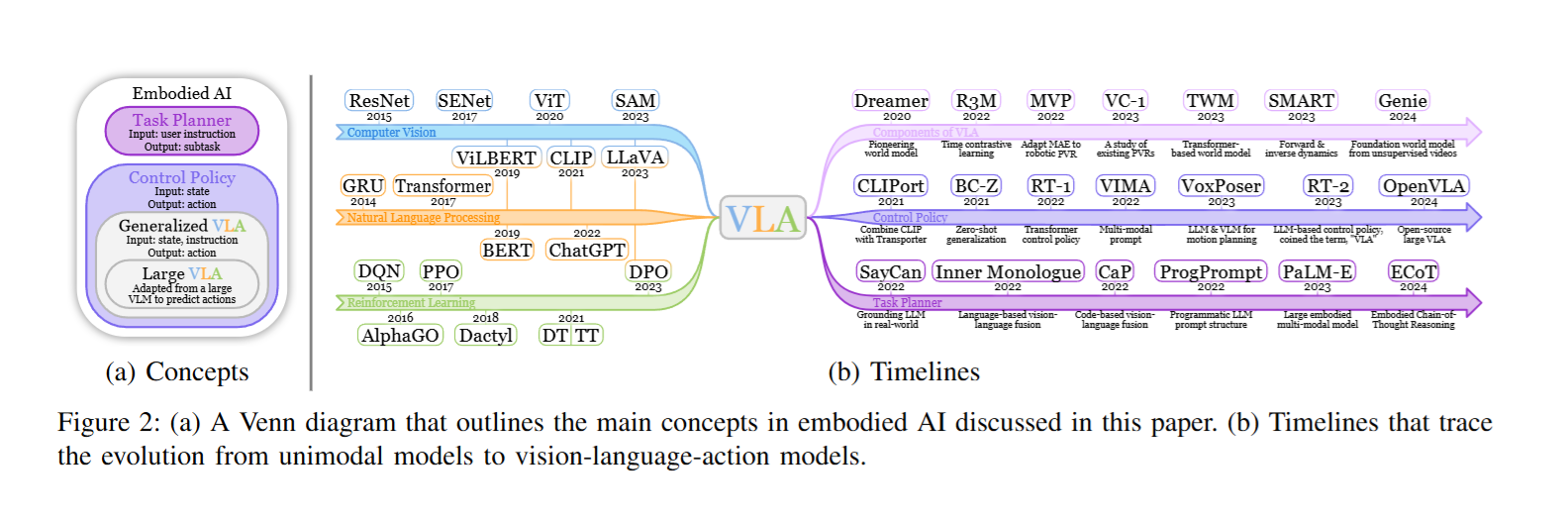
Vision‑Language‑Action(VLA)模型通过融合视觉感知、语言理解与动作生成三大模块,实现了从自然语言指令到具体动作序列的端到端映射。在视觉模块中,预训练编码器(如 CLIP、DINOv2 或基于自监督的 MAE)负责提取环境中物体与场景的语义特征,而世界模型(如 Dreamer 系列)则进一步构建环境动态的内部表征,使得智能体能够在“想象–计划–执行”闭环中进行高效推理。语言模块通常依托大规模预训练语言模型(例如 PaLM‑E、EmbodiedGPT),通过链式思维或任务分解策略,将复杂指令细化为可执行的子任务。动作模块则采用从强化学习(PPO、DQN)到决策 Transformer(Decision Transformer、Gato)甚至扩散策略(Diffusion Policy)的多样化方法,以兼顾动作的精度与多样性。
尽管 VLA 模型在仿真环境下已展现出较为优秀的性能,但在真实场景中,数据稀缺与模型部署带来的效率与安全挑战依然突出。未来研究仍需探索自监督与仿真‑现实域自适应技术,以提升模型在多变环境中的泛化能力;同时,通过模型剪枝、早停推理或部分激活策略(如 TinyVLA 系列)来兼顾实时响应与资源受限设备的部署需求。此外,将安全约束与可解释机制融入动作生成流程,可为具身智能体的实际应用提供更可靠的保障。只有在理论创新与工程实践的双重驱动下,VLA 模型方能从“入门”迈向真正的“精通”与大规模应用。
第一阶段:仿真环境安装与模仿学习流程
🎯阶段目标
完成以下三大核心工具的环境搭建与初步使用:
- Pytorch:深度学习框架
- Isaac Lab:用于任务定义和训练的框架
- RoboMimic:模仿学习库,支持行为克隆(BC)等策略
步骤一:Python + PyTorch 环境准备
🔧学习目标
- 掌握虚拟环境管理(以 Conda 为例)
- 成功安装 PyTorch 并具备 GPU 加速能力
🔧安装流程
conda create -n robosim python=3.10
conda activate robosim
pip install torch==2.1.2+cu118 torchvision torchaudio –index-url https://download.pytorch.org/whl/cu118
✅ 验证安装:
import torch
print(torch.cuda.is_available()) # 应返回 True
🔧推荐中文资源
-Python3基础教程|莫烦
-Pytorch中文网
-B站小土堆|PyTorch深度学习快速入门教程
步骤二:安装 Isaac Lab(任务训练框架)
🔧学习目标:
- 克隆并成功运行 Isaac Lab 示例脚本
- 掌握仿真环境的创建与遥操作演示
🔧安装步骤
git clone https://github.com/NVIDIA-Omniverse/IsaacLab.git
cd IsaacLab
./isaaclab.sh –install
✅ 示例运行验证
./isaaclab.sh -p source/standalone/create_empty.py
🔧示例任务(键盘遥操作)
./isaaclab.sh -p scripts/environments/teleoperation/teleop_se3_agent.py
–task Isaac-Lift-Cube-Franka-IK-Rel-v0
–teleop_device keyboard –num_envs 1
🔧推荐中文资源
步骤三:安装与使用 RoboMimic(模仿学习)
🔧学习目标
- 了解 RoboMimic 支持的策略(BC/BC-RNN等)
- 成功运行一个 BC 模型训练流程
🔧安装步骤
git clone https://github.com/ARISE-Initiative/robomimic.git
cd robomimic
pip install -e .
🏗️ 启动训练示例
python train.py –config exps/templates/bc.json –dataset datasets/dataset.hdf5
训练模型和日志输出会保存在 output/ 目录下。
🔧推荐资源
进阶推荐(模仿学习)
🔧 ACT
- GitHub:github.com/tonyzhaozh/act
🔧ALOHA
- 项目主页:tonyzhaozh.github.io/aloha
- GitHub:github.com/tonyzhaozh/aloha
ALOHA 是一个低成本双臂机器人系统,ACT 是其搭配的动作分块模仿学习策略,支持长时序任务执行。
🧩进阶推荐(Diffusion)
- Diffusion Policy
- 📘 GitHub:github.com/real-stanford/diffusion_policy
- 📄 论文:arxiv.org/abs/2303.04137
哥伦比亚大学与丰田研究院提出,适合高维动作控制任务的扩散策略方法。
- 3D Diffusion Policy (DP3)
- 📘 GitHub:github.com/YanjieZe/3D-Diffusion-Policy
- 🌐 项目主页:dp3.cs.columbia.edu
DP3 将 3D 视觉与扩散策略结合,提升了三维任务中的泛化与控制能力。